Did you know that feedforward Neural Nets (with piecewise linear transfer functions) have no smooth local maxima?
In our recent ICML paper Practical Gauss-Newton Optimisation for Deep Learning) we discuss a second order method that can be applied successfully to accelerate training of Neural Networks. However, here I want to discuss some of the fairly straightforward, but perhaps interesting, insights into the geometry of the error surface that that work gives.
Feedforward Neural Networks
In our description, a feedforward NN takes an input vector and produces a vector on the final layer. We write to be the vector of pre-activation values for layer and to denote the vector of activation values after passing through the transfer function .
Starting with setting to the input , a feedforward NN is defined by the recursion
where is the weight matrix of layer (we use a sub or superscript wherever most convenient) and the activation vector is given by
We define a loss between the final output layer and a desired training output . For example, we might use a squared loss
where the loss is summed over all elements of the vector. For a training dataset the total error function is the summed loss over individual training points
where represents the stacked vector of all parameters of the network. For simplicity we will write for the error for a single generic datapoint.
The Gradient
For training a NN, a key quantity is the gradient of the error
We use this for example in gradient descent training algorithms. An important issue is how to compute the gradient efficiently. Thanks to the layered structure of the network, it’s intuitive that there is an efficient scheme (backprop which is a special case of Reverse Mode AutoDiff) that propagates information from layer to layer.
The Hessian
One aspect of the structure of the error surface is the local curvature, defined by the Hessian matrix with elements
The Hessian matrix itself is typically very large. To make this more manageable, we’ll focus here on the Hessian of the parameters of a given layer . That is
The Hessians then form the diagonal block matrices of the full Hessian .
A recursion for the Hessian
Similar to the gradient, it’s perhaps intuitive that a recursion exists to calculate this layerwise Hessian. Starting from
and differentiating again we obtain
where we define the pre-activation Hessian for layer as
We show in Practical Gauss-Newton Optimisation for Deep Learning that one can derive a simple backwards recursion for this pre-activation Hessian (the recursion is for a single datapoint – the total Hessian is a sum over the individual datapoint Hessians):
where we define the diagonal matrices
and
Here is the first derivative of the transfer function and is the second derivative.
The recursion is initialised with which depends on the objective and is easily calculated for the usual loss functions. For example, for the square loss we have , namely the identity matrix. We use this recursion in our paper to build an approximate Gauss-Newton optimisation method.
Consequences
Piecewise linear transfer functions, such as the ReLU are currently popular due to both their speed of evaluation (compared to more traditional transfer functions such as ) and also the empirical observation that, under gradient based training, they tend to get trapped less often in local optima. Note that if the transfer functions are piecewise linear, this does not necessarily mean that the objective will be piecewise linear (since the loss is usually itself not piecewise linear).
For a piecewise linear transfer function, apart from the `nodes’ where the linear sections meet, the function is differentiable and has zero second derivative, . This means that the matrices in the above Hessian recursion will be zero (away from nodes).
For many common loss functions, such as squared loss (for regression) and cross entropy loss (for classification) the Hessian is Positive Semi-Definite (PSD).
Note that, according to \eqref{eq:recursion}, for transfer functions that contain zero gradient points then the Hessian can have lower rank than , reducing the curvature information propagating back from layers close to the output towards layers closer to the input. This has the effect of creating flat plateaus in the surface and makes gradient based training potentially more problematic. Conversely, provided the gradient of the transfer function is never zero , then according to \eqref{eq:recursion} each layer pre-activation Hessian is Positive Definite, helping preserve the propagation of surface curvature back through the network.
Structure within a layer
For such loss functions, it follows that the pre-activation Hessian for all layers is PSD as well (away from nodes). It immediately follows from \eqref{eq:H} that the Hessian for each layer is PSD. This means that, if we fix all the parameters of the network, and vary only the parameters in a layer , then the objective can exhibit no smooth local maxima or smooth saddle points. Note that this does not imply that the objective is convex everywhere with respect to as the surface will contain ridges corresponding to the non-differentiable nodes.
No differentiable local maxima
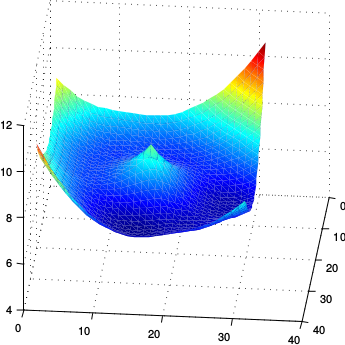
The trace of the full Hessian is the sum of the traces of each of the layerwise blocks . Since (as usual away from nodes) by the above argument each matrix is PSD, it follows that the trace of the full Hessian is non-negative. This means that it is not possible for all eigenvalues of the Hessian to be simultaneously negative, with the immediate consequence that feedforward networks (with piecewise linear transfer functions) have no differentiable local maxima. The picture below illustrates the kind of situtation therefore that can happen in terms of local maxima:

whereas the image below depicts the kind of smooth local maxima that cannot happen:

Visualisation for a simple two layer net
We consider a simple network with two layers, ReLU transfer functions and square loss error. The network thus has two weight matrices and . Below we choose two fixed matrices and and parameterise the weight matrix as a function of two scalars and , so that . As we vary and we then plot the objective function , keeping all other parameters of the network fixed.
As we can see the surface contains no local differentiable local maxima as we vary the parameters in the layer.

Below we show an analogous plot for varying the parameters of the second layer weights , which has the same predicted property that there are no differentiable local maxima.

Finally, below we plot using and , showing how the objective function changes as we simultaneously change the parameters in different layers. As we can see, there are no differentiable maxima.

Summary
A simple consequence of using piecewise linear transfer functions and a convex loss, is that feedforward networks cannot have any differentiable maxima (or saddle points) as parameters are varied within a layer. Furthermore, the objective cannot contain any differentiable maxima, even as we vary parameters across layers. Note that the objective though can (and empirically does) have smooth saddle points as one varies parameters and across different layers.
It’s unclear how practically significant these modest insights are. However, they do potentially partially support the use of piecewise linear transfer functions (particularly those with no zero gradient regions) since for such transfer functions gradient based training algorithms cannot easily dawdle on local maxima (anywhere), or idle around saddle points (within a layer) since such regions correspond to sharp slopes in the objective.
These results are part of a more detailed study of second order methods for optimisation in feedforward Neural Nets which will appear in ICML 2017.
 Evolutionary Optimization as a Variational Method
Evolutionary Optimization as a Variational Method