How popular evolutionary style optimisation methods can be viewed as optimisation of a rigorous bound.
Variational Optimization is based on the bound
That is, the minimum of a collection of values is always less than their average. By defining
instead of minimising with respect to , we can minimise the upper bound with respect to . Provided the distribution is rich enough, this will be equivalent to minimising .
The gradient of the upper bound is then given by
which is reminiscent of the REINFORCE (Williams 1992) policy gradient approach in Reinforcement Learning.
In the original VO report and paper this idea was used to form a differentiable upper bound for non-differentiable and also discrete .
Sampling Approximation
There is an interesting connection to evolutionary computation (more precisely Estimation of Distribution Algorithms) if the expectation with respect to is performed using sampling. In this case one can draw samples from and form an unbiased approximation to the upper bound gradient
The “evolutionary” connection is that the samples can be thought of as “particles” or “swarm members” that are used to estimate the gradient. Based on the approximate gradient, simple Stochastic Gradient Descent (SGD) would then perform the parameter update (for learning rate )
The “swarm” then disperses and draws a new set of members from and the process repeats.
A special case of VO is to use a Gaussian so that (for the scalar case – the multivariate setting follows similarly)
Then the gradient of this upper bound is given by
By changing variable this is equivalent to
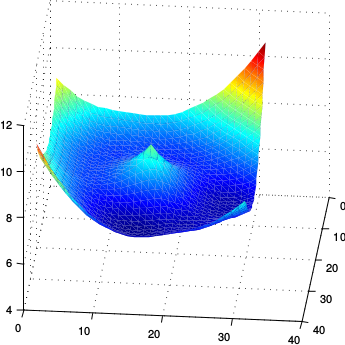
Fixing and using samples, we show below the trajectory (for 150 steps of SGD with fixed learning rate ) of based on Stochastic VO and compare this to the underlying function (which in this case is a simple quadratic). Note that we only plot below the parameter trajectory (each red dot represents a parameter , with the initial parameter in the bottom right) and not the samples from . As we see, despite the noisy gradient estimate, the parameter values move toward the minimum of the objective . The matlab code is available if you’d like to play with this.

One can also consider the bound as a function of both the mean and variance :
and minimise the bound with respect to both and (which we will parameterise using to ensure a positive variance). More generally, one can consider parameterising the Gaussian covariance matrix for example using factor analysis and minimsing the bound with respect to the factor loadings.
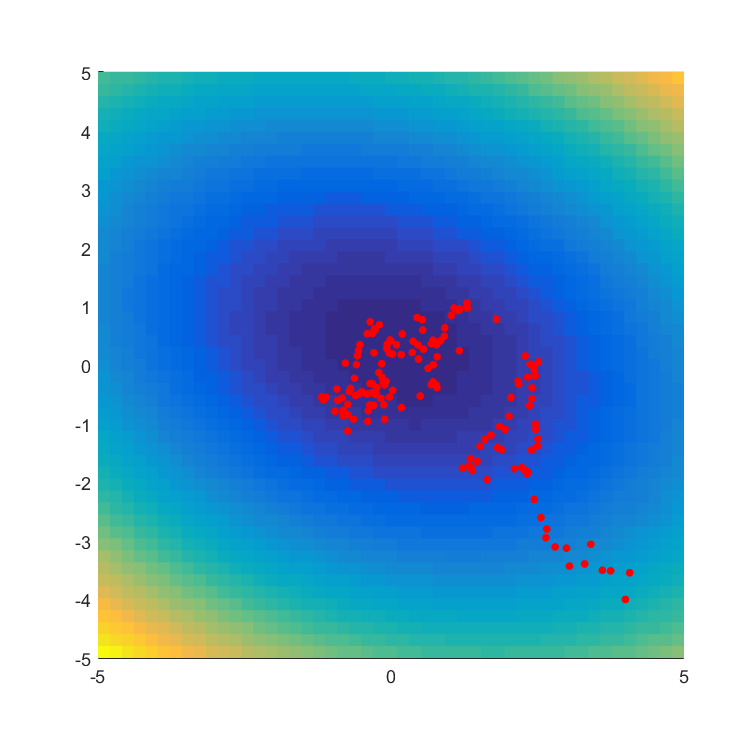
Using a Gaussian with covariance and performing gradient descent on both and , for the same objective function, learning rate and initial , we obtain the trajectory below for

As we can see, by learning , the trajectory is much less noisy and more quickly homes in on the optimum. The trajectory of the learned standard deviation is given below, showing how the variance reduces as we home in on the optimum.

In the context of more general optimisation problems (such as in deep learning and reinforcement learning), VO is potentially interesting since the sampling process can be distributed across different machines.
Gradient Approximation by Gaussian Perturbation
Ferenc Huszar has a nice post Evolution Strategies: Almost Embarrassingly Parallel Optimization summarising recent work by Salimans etal on Evolution Strategies as a Scalable Alternative to Reinforcement Learning.
The aim is to minimise a function by using gradient based approaches, without explicitly calculating the gradient. The first observation is that the gradient can be approximated by considering the Taylor expansion
Multiplying both sides by
Finally, taking the expectation with respect to drawn from a Gaussian distribution with zero mean and variance we have
Hence, we have the approximation
Based on the above discussion of VO, and comparing equations (1) and (2) we see that this Gaussian perturbation approach is related to VO in which we use a Gaussian , with the understanding that in the VO case the optimisation is over rather than . An advantage of the VO approach, however, is that it provides a principled way to adjust parameters such as the variance (based on minimising the upper bound).
Whilst this was derived for the scalar setting, the vector derivative is obtained by applying the same method, where the vector is drawn from the zero mean multivariate Gaussian with covariance for identity matrix .
Efficient Communication
A key insight in Evolution Strategies as a Scalable Alternative to Reinforcement Learning is that the sampling process can be distributed across multiple machines, so that
where is a vector sample and is the sample index. Each machine can then calculate . The Stochastic Gradient parameter update with learning rate is
Provided each machine also knows the random seed used to generate the of each other machine, it therefore knows what all the are (by sampling according to the known seeds) and can thus calculate based on only the scalar values calculated by each machine. The basic point here is that, thanks to seed sharing, there is no requirement to send the vectors between the machines (only the scalar values need be sent), keeping the transmission costs very low.
Based on the insight that the Parallel Gaussian Perturbation approach is a special case of VO, it would be natural to apply VO using seed sharing to efficiently parallelise the sampling. This has the benefit that other parameters such as the variance can also be efficiently communicated, potentially significantly speeding up convergence.
Further Work
In our paper1 we show that approaches such as Natural Evolution Strategies and Gaussian Perturbation, are special cases of Variational Optimization in which the expectations are approximated by Gaussian sampling. These approaches are of particular interest because they are parallelizable. We calculate the approximate bias and variance of the corresponding gradient estimators and demonstrate that using antithetic sampling or a baseline is crucial to mitigate their problems. We contrast these methods with an alternative parallelizable method, namely Directional Derivatives. We conclude that, for differentiable objectives, using Directional Derivatives is preferable to using Variational Optimization to perform parallel Stochastic Gradient Descent.
References
-
T.Bird, J. Kunze, D. Barber. Stochastic Variational Optimization. arxiv.org/abs/1809.04855, 2018. ↩
 Training with a large number of classes
Training with a large number of classes