
How can we train generative models when we cannot calculate a gradient likelihood?
A popular class of models in machine learning is the so-called generative model class with deterministic outputs. These are currently used for example in the generation of realistic images. If we represent an image with the variable , then these models generate an image by the following process:
-
Sample from a dimensional Gaussian (multivariate-normal) distribution.
-
Use this as the input to a deep neural network whose output is the image .
Typically the dimension of the latent variable is chosen to be much lower than the observation variable . This enables one to learn a low-dimensional representation of high-dimensional observed data.
We can write this mathematically as a latent variable model producing a distribution over images , with
and restricted to a deterministic distribution so that
where we write to emphasise that the model depends on the parameters of the network. These models represent a rich class of distributions (thanks to the highly non-linear neural network) and are also easy to sample from (using the above procedure).
So what’s the catch? Given a set of training images, , the challenge is to learn the parameters of the network .
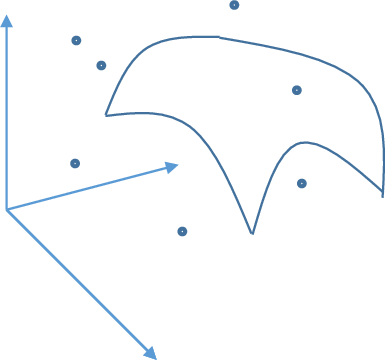
Because the latent dimension is lower than the observation dimension , the model can only generate images in a dimensional manifold within the dimensional image space, as depicted in the figure for a latent dimension and observed dimension . That means that only images that lie on this manifold will have non-zero probability density value. For an image from the training dataset, unless it lies exactly on the manifold, the likelihood of this image will be zero. This means that typically the log likelihood of the dataset
is not well defined and standard gradient based training of is not possible. This is a shame because (i) many standard training techniques are based on maximum likelihood and (ii) maximum likelihood is statistically efficient, meaning that no other training method can more accurately learn the model parameters .
The inappropriateness of maximum likelihood as the training criterion for this class of models has inspired much recent work. For example the GAN objective and MMD objectives are well known approaches to training such models1. However, it is interesting to consider whether one can nevertheless modify the maximum likelihood criterion to make it applicable in this situation. The beauty of doing so is that we may then potentially use standard maximum likelihood style techniques (such as variational training approaches).
The Spread Divergence
For concreteness, we consider the Kullback-Leibler Divergence divergence between distributions and
Maximising the likelihood is equivalent to minimising the KL Divergence between the empirical data distribution
and the model , since
The fact that maximum likelihood training is not appropriate for deterministic output generative models is equivalent to the fact that the KL divergence (and its gradient) are not well defined for this class of model.
More generally, for distributions and , the -Divergence is defined as
where is a convex function with . However, this divergence may not be defined if the supports (regions of non-zero probability) of and are different, since then the ratio can cause a division by zero. This is the situation when trying to define the likelihood for data that is not on the low dimensional manifold of our model.
The central issue we address therefore is how to convert a divergence which is not defined due to support mismatch into a well defined divergence.
From and we define new distributions and that have the same support. We define distributions
where ‘spreads’ the mass of and and is chosen such that and have the same support.
Consider the extreme case of two delta distributions
for which is not well defined. Using a Gaussian spread distribution with mean and variance ensures that and have common support . Then
and
and the KL divergence between the two becomes
This divergence is well defined for all values of and . Indeed, this divergence has the convenient property that . If we consider to be our data distribution (a single datapoint at ) and our model , we can now do a modified version of maximum likelihood training to fit to – instead of minimising , we minimise .
Note that, in general, we must spread both distributions and for the divergence between the spreaded distributions to be zero to imply that the original distributions are the same. In the context of maximum likelihood learning, spreading only one of these distributions will in general result in a biased estimator of the underlying model.
Stationary Spread Divergence
If we consider stationary spread distributions of the form , for ‘kernel’ function . It is straightforward to show that if the kernel has strictly positive Fourier Transform, then
Interestingly, this condition on the kernel is equivalent to the condition on the kernel in the MMD framework2, which is an alternative way to define a divergence between distributions. It is easy to show that the Gaussian distribution has strictly positive Fourier Transform and thus defines a valid spread divergence. Another useful spread distribution with this property is the Laplace distribution.
Machine Learning Applications
We now return to how to train models of the form
and adjust the parameters to make the model fit the data distribution
Since maximum likelihood is not (in general) available for this class of models, we instead consider minimising the spread KL divergence using Gaussian spread noise
where the spreaded data distribution is
The objective is then simply an expectation over the log likelihood ,
which is a standard generative model with a Gaussian output distribution. For this we may now use a variational training approach to form a lower bound on the quantity . The final objective just then requires evaluating the expectation of this bound, which can be easily approximated by sampling from the spreaded data distribution.
Overall, this is therefore a simple modification of standard Variational Autoencoder (VAE) training in which there is an additional outer loop sampling from the spreaded data distribution3.
In the figure below we show how we are able to fit a deep generative 4 layer convolutional network with deterministic output to the CelebA dataset of face images. Whilst this model cannot be trained using standard VAE approaches, using the spread divergence approach and sampling from the trained model gives images of the form below

Our aim isn’t to produce the most impressive face sampler, but rather to show how one can make a fairly simple modification of the standard training algorithm to cope with deterministic outputs.
In our paper3 we apply this method to show how to overcome well known problems in training deterministic Independent Components Analysis models using only a simple modification of the standard training algorithm. We also discuss how to learn the spread distribution and how this relates to other approaches such as MMD and GANs.
Summary
A popular class of generative deep network models cannot be trained using standard classical machine learning approaches. However, by adding ‘noise’ to both the model and the data in an appropriate way, one can nevertheless define an appropriate objective that is amenable to standard machine learning training approaches.
References
-
S. Mohamed and B. Lakshminarayanan. Learning in Implicit Generative Models. arxiv.org/abs/1610.03483, 2016. ↩
-
A. Gretton et al. A Kernel Two-Sample Test. Journal of Machine Learning Research, 13. 2012. ↩
-
M. Zhang, P. Hayes, T. Bird, R. Habib, D. Barber. Spread Divergence. arxiv.org/abs/1811.08968, 2018. ↩ ↩2
 UCL AI Centre
UCL AI Centre